[KEMBALI KE MENU SEBELUMNYA]
.
HIDDEN MARKOV MODEL
1. Tujuan
a. Mampu Memahami mengenai Hidden Markov Model
b. Dapar mengaplikasikan Hidden Markov Model dalam
sebuah permasalahan
2. Alat & Bahan
a. Aplikasi Google Colab
3. Materi
Hidden Markov Model (HMM)
adalah sebuah model statistik dari sebuah sistem yang diasumsikan
sebuah Proses Markov dengan parameter yang tak diketahui, dan tantangannya
adalah menentukan parameter-parameter tersembunyi (state) dari
parameter-parameter yang dapat diamati (observer).
Algoritma HMM yang digunakan sebagai teknik dasar untuk
automatic speech recognition (ASR) dan part-of-speech (POS)
tagging. HMM adalah salah satu metode
Bayesian Inference pada pattern recognition dan
machine learning.
A. Probabilistic Reasoning
Probabilistic Reasoning adalah suatu yang memiliki kemampuan mengambil
keputusan yang rasional walaupun informasi yang akan diolah kurang
lengkap atau bersifat nonlinier.

B. Generative Model
Pada Generative model memodelkan p(x,y). Persamaan ini dapat
difaktorkan sebagai p(x,y) = p(y | x)p(x). Pada umumnya kita lebih
tertarik dengan nilai y yang menyebabkan p(x,y) bernilai maksimum,
berhubung x akan selalu tetap karena x adalah fixed input, y terbaiklah
yang ingin kita temukan. Berbeda dengan supervised learning, generative
model dapat difaktorkan menjadi p(y | x) dan p(x). Karena berbentuk joint
probability, generative model memodelkan peluang kemunculan
bersamaan.
Salah satu generative model adalah
Hidden Markov Model (HMM). HMM memodelkan observasi menggunakan proses
Markovian dengan state yang tidak diketahui secara jelas (hidden).
C. Part-of-speech Tagging
Pada bidang pemrosesan bahasa alami (natural language
processing), peneliti tertarik untuk mengetahui kelas kata untuk
masing - masing kata di tiap kalimat. Misalkan kamu diberikan sebuah
kalimat " Budi menendang bola:. Setelah proses POS tagging, kamu
mendapat "Budi/Noun menendang/Verb bola/Noun".
Hal ini sangat berguna pada bidang pemrosesan bahasa
alami, misalkan untuk memilih noun pada kalimat. Kelas kata
disebut sebagai syntactic categories. Pada bahasa inggris
dikenal dengan Penn Treebank Pos Tags.
POS tagging adalah salah satu bentuk pekerjaan
sequential classification. Diberikan sebuah sekuens kata
(membentuk satu kalimat), kita ingin menentukan kelas setiap
kata/token pada kalimat tersebut. Kita ingin memilih sekuens
kelas kata syntactic categories yang paling cocok untuk
kata-kata/tokes pada kalimat yang diberikan. Secara formal,
diberikan sekuens kata - kata w1, w2, ... ,wr, kita ingin
mencari sekuens kelas kata c1, c2, ... ,cr, sedemikian
sehingga kita memaksimalkan nilai probabilitas.


D. Hidden Markov Model Tagger
Markov chain adalah kasus spesial
weighted automaton yang mana sekuens input menentukan
states yang akan dilewati oleh automaton. Sederhananya,
automaton mencapai goal states setelah mengunjungi
berbagai states. Total bobot outgoing edges untuk masing
- masing state pada automaton haruslah bernilai satu
apabila dijumlahkan kasus spesial yang yang dimaksud
adalah emission.
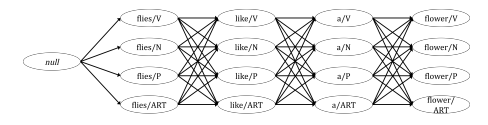
Sebagai Contoh pada gambar. ART adalah
article, N adalah noun, V adalah verb dan P adalah
preposition. Mereka adalah contoh kelas kata yang
disederhanakan demi membuat contoh yang mudah. Tabel
dibawah mempresentasikan probabilitas kelas kata,
ketika dikonversi menjadi weighted automaton.



Seumpama kita mempunyai lexical emission probabilities seperti pada tabel. Setiap state pada automaton, dapat menghasilkan/meng-outputkan suatu kata (word) dengan probabilitas pada tabel kita bisa mengembangkan gambar weighted aytomaton tadi menjadi

Automaton ini disebut hidden markov model
(HMM). Kata hidden berarti, untuk setiap kata pada
sekuens, kita tidak mengetahui kata tersebut dihasilkan
oleh state mana secara model. Misalkan kata flies dapat
dihasilkan oleh state N(noun) atau V(verb).
E. Algoritma Viterbi
Algoritma Viterbi adalah salah satu
algoritma dynamic programing yang prinsip kerjanya mirip
dengan minimum edit distance. Ide utama algoritma
viterbi adalah mengingat sekuens untuk setiap posisi
tertentu( setiap iterasi, setiap panjang kalimat).
apabila kita telah smpai pada kata terakhir, kita
lakukan backtrace untuk mendapatkan sekuens
terbaik.

Pada gambar diatas menunjukkan pseudo-code
untuk algoritma Viterbi. Variabel c berarti kelas kata, a
adalah transition probability, dan b adalah
lexical-generation probability. Pertama-tama algoritma
tersebut membuat suatu matrik berukuran SxT dengan S adalah
banyaknya states ( tidak termasuk start state ) dan T (time)
adalah panjang sekuens. Pada setiap iterasi, kita pindah ke
observasi kata lainnya.

Gambat diatas adalah ilustrasi algoritma Viterbi untuk
kalimat input (observed sequence ) "flies like a flowe"
dengan lexical generation probability pada Lexical
emisson probabilities dan transition probabilities pada
probabilitas bigram.
Panah bewarna merah melambangkan
backpointer yaitu state mana yang memberikan nilai
tertinggi untuk melambangkan backpointer yaitu state
mana yang memberikan nilai tertinggi untuk ekspansi ke
state berikutnya. Setelah iteration step selesai, kita
lakukan backtrace terhadap state terakhir yang
memiliki nilai probabilitas tertinggi dan mendapat
hasil seperti pada gambar dibawah.

Hidden Markov Model (HMM) adalah salah satu varian supervised learning, diberikan sekuens input dan output yang bersesuaian sebagai training data. Pada kasus POS tagging, yaitu inputnya adalah sekuens kata dan outputnya adalah sekuens kelas kata ( masing - masing kata/token berkorepondensi dengan kelas kata). Saat melatih HMM, kita ingin mengestimasi parameter A dan B yaitu transition probabilities dan emission probabilities/lexical-generation probabilitie. Kita melatih dengan menggunakan algoritma Forward-Backward (Baum-Welch Algorithm).

|
|
Algoritma forward |

|
|
Algortima backward |

|
| Algoritma forward-backward (EM) |
Keseluruhan proses ini adalah cara melatih HMM dengan menggunakan kerangka berpikir Expectation Maximization : terdiri dari E-step dan M-step. Walaupun HMM menggunakan independence assumption, tetapi kita dapat mengikutsertakan pengaruh probabilitas keseluruhan sekuens untuk perhitungan probabilitas keberadaan kita pada suatu state i pada saat (time t) tertentu.
4. Percobaan
HMM using the Viterbi Algorithm.
Code Implementation: Parts Of Speech Tagging

Output :





Setelah mendapatkan Treebank Pos Tag sekarang bisa kita mencobakan beberapa example :




Terakhir kita juga bisa melihat gambaran jumlah kata corpus dengan part of speech-nya.

Outputnya :



