Sumber : Pengenalan Konsep Pembelajaran Mesin dan Deep Learning Oleh Jan Wira
Gotama Putra
[KEMBALI KE MENU SEBELUMNYA]
.
Pengenalan Dasar Machine Learning
1. Tujuan
a. Mampu Memahami mengenai Dasar - dasar Machine Learning
b. Dapar mengaplikasikan Machine Learning dalam
sebuah permasalahan
2. Alat & Bahan
a. Aplikasi Google Colab
3. Materi
1. Kecerdasan Buatan
Berbeda dengan program biasa yang menghasilkan aksi berdasarkan instruksi, tujuan kecerdasan buatan adalah menciptakan program yang mampu mem-program (output program adalah sebuah pro- gram).
Sama halnya dengan program pada umumnya, agen kecerdasan bu- atan juga menjalankan suatu instruksi. Yang menjadikanya beda dengan pro- gram biasa adalah kempuannya untuk belajar.
Agen cerdas memiliki empat kategori berdasarkan kombinasi dimensi cara inferensi (reasoning ) dan tipe kelakuan (behaviour ). Tabel ini menujukkan hubungan antara inferensi dan kelakuan (reasoning and behavior).

- Acting Humanly . Pada dimensi ini, agen mampu bertingkah dan berin- teraksi layaknya seperti manusia. Contoh terkenal untuk hal ini adalah turing test. Terdapat kesalahan layaknya manusia
- Acting Rationally . Pada dimensi ini, agen mampu bertingkah dengan optimal.
- Thinking Humanly . Pada dimensi ini, agen mampu berpikir seperti manusia dalam segi kognitif
- Thinking Ratioanlly: Pada dimensi ini berfikir secara matematis tanpa ada input yang sifatnya manusiawi.
3.Memahami konsep "Belajar" dalam machine learning.
Pembelajaran adalah proses, cara, perbuatan atau men- jadikan orang atau makhluk hidup belajar. Akan tetapi, pada machine learn- ing, yang menjadi siswa bukanlah makhluk hidup, tapi mesin. Secara op- erasional, belajar adalah perubahan tingkah laku berdasarkan pengalaman (event /data) untuk menjadi lebih baik. Pada konteks machine learning, bela- jar adalah menyesuaikan konfigurasi parameter (tingkah laku) terhadap utility function sesuai dengan data (lingkungan).
contoh : Algoritma pada Youtube
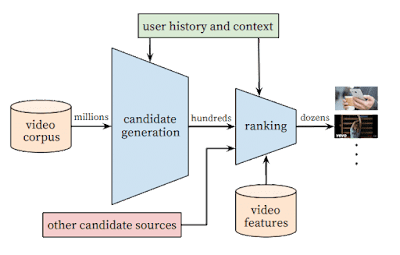 |
| sumber: tasty edits |
Algoritma YouTube selalu berganti, tapi ada setidaknya dua faktor utama yang selalu diperhatikan oleh YouTube yakni engagement. YouTube akan menilai seberapa banyak penonton yang memberikan komen, like, dan membagikan videomu. YouTube juga akan melihat bagaimana engagement tersebut. Apakah positif atau negatif.
Faktor selanjutnya adalah, metadata. Selain engagement, YouTube juga perlu memastikan bahwa metadata yang kamu cantumkan mulai dari judul, keywords, hingga deskripsi sesuai dengan yang dicari oleh pengguna YouTube.
4. Statistical learning theorem
Untuk mencapai tujuan mempermudah sortir data , kita menggunakan data (sampel), kemudian membuat model untuk menggeneralisasi “aturan” atau “pola” data se- hingga kita dapat menggunakannya untuk mendapatkan informasi/membuat keputusan.
Tujuan machine learning minimal ada dua:
- mem- prediksi masa depan (unobserved event );
- dan/atau memperoleh ilmu pengetahuan (knowledge discovery/discovering unknown structure).
Untuk itu Statistical learning theory (yang diaplikasikan pada machine learning) adalah teknik untuk memprediksi masa depan dan/atau meny- impulkan/mendapatkan pengetahuan dari data secara rasional dan non- paranormal. Hal ini sesuai dengan konsep intelligent agent, yaitu bertingkah berdasarkan lingkungan.
- yang bertindak sebagai lingkungan adalah data.
- Performance measure-nya adalah seberapa akurat prediksi agen
contoh: Perbedaan data untuk populasi jenis makanan berbetuk segi empat, bintang dan hati
Karena terdapat perbedaan pada sampel maka m
esin dilatih menggunakan training data, kemudian diuji kinerjanya menggunakan validation data9 dan test data.
5. Training, validation, testing set
Terdapat dua istilah penting dalam pembangunan model machine learning yaitu: training dan testing
- Training set adalah himpunan data yang digunakan untuk melatih atau membangun model. Pada buku ini, istilah training data(set) mengacu pada training set.
- Development set atau validation set adalah himpunan data yang di- gunakan untuk mengoptimisasi saat melatih model.
- Testing set adalah himpunan data yang digunakan untuk menguji model setelah proses latihan selesai
Pasangan input–desired output ini disebut sebagai instance (untuk kasus supervised learning). Pembelajaran metode ini disebut supervised karena ada yang memberikan contoh jawaban (desired output ). Tujuan supervised learning, secara umum untuk melakukan klasifikasi (classification). Misalkan mengklasifikasikan gambar buah (apa nama buah pada gambar). Apabila hanya ada dua kate- gori, disebut binary classification. Sedangkan bila terdapat lebih dari dua kategori, disebut multi-class classification.
contoh:
7. Semi Supervised Learning
Semi-supervised learning mirip dengan supervised learning, bedanya pada proses pelabelan data. Pada supervised learning, ada “guru” yang harus mem- buat “kunci jawaban” input-output. Sedangkan pada semi-supervised learning tidak ada “kunci jawaban” eksplisit yang harus dibuat guru. Kunci jawaban ini dapat diperoleh secara otomatis (misal dari hasil clustering ).
8. Non-Supervised Learning
Jika pengelompokan dalam supervised learning disebut klasifikasi, maka pengelompokan di unsupervised learning disebut pengelompokan atau clustering.
Clustering adalah pengelompokan objek atau titik data yang mirip satu sama lain dan berbeda dengan objek di cluster lain. Machine learning engineer dan data science menggunakan algoritma yang berbeda dalam proses clustering.
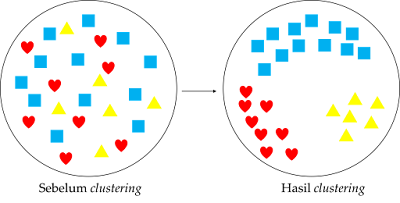 |
Clustering
|
4. Percobaan
Clustering adalah pengelompokan objek atau titik data yang mirip satu sama lain dan berbeda dengan objek di cluster lain.
Hasilkan set data pengujian untuk Machine learning
# importing libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# initialize the parameters for the normal
# distribution, namely mean and std.
# deviation
# defining the mean
mu = 0.5
# defining the standard deviation
sigma = 0.1
# The random module uses the seed value as a base
# to generate a random number. If seed value is not
# present, it takes the system’s current time.
np.random.seed(0)
# define the x co-ordinates
X = np.random.normal(mu, sigma, (395, 1))
# define the y co-ordinates
Y = np.random.normal(mu * 2, sigma * 3, (395, 1))
# plot a graph
plt.scatter(X, Y, color = 'g')
plt.show()
Pengelompokan data
# importing libraries
import numpy as np
import pandas as pd
import math
import random
import matplotlib.pyplot as plt
# defining the columns using normal distribution
# column 1
point1 = abs(np.random.normal(1, 12, 100))
# column 2
point2 = abs(np.random.normal(2, 8, 100))
# column 3
point3 = abs(np.random.normal(3, 2, 100))
# column 4
point4 = abs(np.random.normal(10, 15, 100))
# x contains the features of our dataset
# the points are concatenated horizontally
# using numpy to form a feature vector.
x = np.c_[point1, point2, point3, point4]
# the output labels vary from 0-3
y = [int(np.random.randint(0, 4)) for i in range(100)]
# defining a pandas data frame to save
# the data for later use
data = pd.DataFrame()
# defining the columns of the dataset
data['col1'] = point1
data['col2'] = point2
data['col3'] = point3
data['col4'] = point4
# plotting the various features (x)
# against the labels (y).
plt.subplot(2, 2, 1)
plt.title('col1')
plt.scatter(y, point1, color ='r', label ='col1')
plt.subplot(2, 2, 2)
plt.title('Col2')
plt.scatter(y, point2, color = 'g', label ='col2')
plt.subplot(2, 2, 3)
plt.title('Col3')
plt.scatter(y, point3, color ='b', label ='col3')
plt.subplot(2, 2, 4)
plt.title('Col4')
plt.scatter(y, point4, color ='y', label ='col4')
# saving the graph
plt.savefig('data_visualization.jpg')
# displaying the graph
plt.show()
5. Video
6. Download file








Tidak ada komentar:
Posting Komentar