Klasifikasi Algoritma Genetika
A. Algoritma Genetika Sederhana (SGA)
Mekanisme algoritma genetika sederhana (SGA) secara mengejutkan sederhana yang melibatkan tidak lebih kompleks daripada menyalin string dan menukar string parsial. Algoritme genetik sederhana yang menghasilkan hasil yang baik dalam banyak masalah praktis terdiri dari tiga operasi. Yaitu :
1) Reproduksi
2) Cross over dan
3) Mutasi
Reproduksi adalah proses di mana string individu disalin sesuai dengan nilai fungsi tujuan mereka.
SGA berguna dan efisien ketika,
• Ruang pencarian luas, kompleks atau kurang dipahami.
• Pengetahuan domain adalah pengetahuan langka atau pakar sulit disandikan untuk mempersempit ruang pencarian.
• Tidak tersedia analisis matematika.
• Metode pencarian tradisional gagal.
Keuntungan dari pendekatan SGA adalah kemudahannya dalam menangani berbagai kendala dan tujuan yang sewenang-wenang; semua hal seperti itu dapat ditangani sebagai komponen tertimbang dari fungsi kebugaran, membuatnya mudah untuk menyesuaikan penjadwal SGA dengan persyaratan khusus dari berbagai tujuan keseluruhan yang mungkin sangat luas.
B. Algoritma Genetika Paralel dan Terdistribusi (PGA dan DGA)
Eksekusi paralel berbagai SGA disebut PGA (Parallel Genetic Algorithm). Ini digunakan untuk menyelesaikan masalah penjadwalan Job shop dengan memanfaatkan berbagai kendala prioritas untuk mencapai optimalisasi tinggi.
PGA dapat dengan mudah diimplementasikan pada jaringan komputer heterogen atau pada mainframe paralel. Cara GAS dapat diparalelkan tergantung pada elemen-elemen berikut:
• Bagaimana kebugaran dievaluasi dan mutasi diterapkan
• Bagaimana seleksi diterapkan secara lokal atau global
• Jika subpopulasi tunggal atau ganda digunakan
• Jika banyak populasi digunakan bagaimana individu dipertukarkan
Cara paling sederhana untuk memparalelkan GA adalah dengan mengeksekusi beberapa salinan SGA yang sama, satu pada setiap Elemen Pemrosesan (PE). Masing-masing PE dimulai dengan subpopulasi awal yang berbeda, berevolusi, dan berhenti secara independen. PGA lengkap berhenti ketika semua PE berhenti. Tidak ada komunikasi antar-PE. Berbagai metode PGA adalah:
• PGA Independen
• PGA Migrasi
• PGA Partisi
• Segmentasi PGA
• Segmentasi - PGA Migrasi
1. Paralelisasi Master-Slave

Skema GA paralel master-slave. Master menyimpan populasi, mengeksekusi operasi GA, dan mendistribusikan individu ke budak. Budak hanya mengevaluasi kecukupan individu
Bagian ini mengulas metode paralelisasi master-slave (atau global). Algoritma menggunakan populasi tunggal dan evaluasi individu dan / atau aplikasi operator genetik dilakukan secara paralel. Seperti dalam GA seri, setiap individu dapat bersaing dan kawin dengan yang lain (sehingga pemilihan dan kawin adalah global). Global parallel GAS biasanya diimplementasikan sebagai program master-slave (Gbr. ), di mana master menyimpan populasi dan harga slavese pada kebugaran. Operasi paling umum yang diparalelkan adalah evaluasi individu, karena kecukupan individu tidak tergantung dari sisa populasi, dan tidak perlu berkomunikasi selama fase ini.
Jumlah individu yang ditugaskan untuk prosesor apa pun mungkin konstan, tetapi dalam beberapa kasus (seperti dalam lingkungan multiuser di mana pemanfaatan prosesor adalah variabel) mungkin diperlukan untuk menyeimbangkan beban komputasi di antara prosesor dengan menggunakan algoritma penjadwalan dinamis (misalnya, algoritma penjadwalan dinamis (mis. , penjadwalan mandiri terpandu). Berikut ini adalah deskripsi informal dari algoritma:

2. GAS Paralel Berbutir Halus (GAS Seluler)
Dalam kisi-kisi atau model model berbutir halus, setiap individu ditempatkan pada kisi-kisi toroidal besar (ujung membungkus) satu atau dua dimensi, satu individu per lokasi kisi. Model ini juga disebut seluler karena kemiripannya dengan automata seluler dengan aturan transisi stokastik. Evaluasi kebugaran dilakukan secara bersamaan untuk semua individu dan seleksi, reproduksi, dan perkawinan berlangsung secara lokal di lingkungan kecil. Pada waktunya, ceruk semi-terisolasi dari individu yang secara genetik homogen muncul di seluruh jaringan sebagai akibat dari difusi individu yang lambat. Fenomena ini disebut isolasi oleh jarak dan disebabkan oleh kenyataan bahwa kemungkinan interaksi dua individu adalah fungsi peluruhan jarak mereka yang cepat.

Skema GA paralel berbutir halus. Kelas GAS paralel ini memiliki satu populasi berdistribusi spasial, dan dapat diimplementasikan dengan sangat efisien pada komputer paralel masif


3. GAs Paralel Multi-Deme (GAS Terdistribusi atau GAS Berbutir Kasar)
GAs multi populasi (atau multi-deme) lebih canggih, karena mereka terdiri atas beberapa subpopulasi yang kadang-kadang bertukar individu (Gbr. ). Pertukaran individu ini disebut migrasi, seperti dibahas di atas; ia dikontrol oleh beberapa parameter. Beberapa demisiasi lebih populer, tetapi juga kelas GAS paralel, yang paling sulit dipahami, karena efek migrasi tidak sepenuhnya dipahami. GAS paralel multi-deme memperkenalkan perubahan mendasar dalam pengoperasian GA dan memiliki perilaku yang berbeda dari GAS sederhana.

Skema GA paralel multi-populasi. Setiap proses adalah GA sederhana, dan ada (jarang) komunikasi antara populasi
Berikut ini adalah deskripsi algoritmik dari proses tersebut:

4. Algoritma Paralel Hierarkis
Metode terakhir untuk memparalelkan GAS menggabungkan beberapa demes dengan master-slave atau edge grain-halus. Secara keseluruhan disklasifikasi dari algoritma dengan hierarki paralel, karena pada tingkat yang lebih tinggi mereka adalah algoritma multi-deme dengan satu populasi paralel GAS (baik master-slave atau serat halus) di tingkat yang lebih rendah. GAS paralel hierarkis menggabungkan manfaat komponen-komponennya, dan menjanjikan kinerja yang lebih baik daripada komponen-komponen itu sendiri. Beberapa peneliti telah mencoba untuk menggabungkan dua metode untuk memparalelisasi GAS, menghasilkan hierarki paralel GAS. Beberapa algoritma hibrid baru ini menambah tingkat kompleksitas baru ke adegan GAS paralel yang sudah rumit, tetapi hibrida lain berhasil mempertahankan kompleksitas yang sama dengan salah satu komponennya. Ketika dua metode paralelisasi GAS digabungkan mereka membentuk hierarki. Pada tingkat atas, sebagian besar paralel hibrida GAS adalah algoritma multi-populasi. Beberapa hibrida memiliki butiran-butiran halus pada tingkat yang lebih rendah (Gbr. ).

GA hirarkis ini menggabungkan multi-deme GA (di tingkat atas) dan GA berbutir halus (di tingkat bawah)
Tipe lain dari hierarki paralel paralel menggunakan salah satu dari slave-slave dari tema multi-populasi GA (Gbr.). Migrasi terjadi di antara demes, dan evaluasi individu secara individual dan diatasi secara paralel. Pendekatan ini tidak menimbulkan masalah analitik baru, dan dapat berguna saat bekerja dengan aplikasi yang kompleks dengan fungsi objektif yang membutuhkan jumlah yang cukup besar dari perhitungan waktu. Bianchini dan Brown memberikan contoh metode hibridisasi paralel GAs ini, dan menunjukkan bahwa metode ini dapat menemukan solusi dengan kualitas yang sama dari GA paralel-master-slave atau GA multi-deme dalam waktu yang lebih singkat.

skematis dari paralel GA hirarkis. Pada tingkat atas hibrida ini adalah multi-deme parallel GA di mana setiap node adalah master-slave GA
Jadi, algoritma multi-deme jarang melakukan penelitian pada GA paralel. Kelas GAS paralel sangat kompleks, dan perilakunya dipengaruhi oleh banyak parameter. Tampaknya satu-satunya cara untuk mencapai pemahaman yang lebih besar tentang GA paralel adalah dengan mempelajari aspek individual secara independen, dan kami telah melihat bahwa beberapa GA paling paralel berkonsentrasi pada tingkat migrasi, topologi, atau ukuran deme. Karena GA diterapkan untuk masalah pencarian yang lebih besar dan lebih sulit, maka perlu dirancang algoritma yang lebih cepat yang mempertahankan kemampuan menemukan solusi yang dapat diterima. Bagian ini menyajikan banyak GA paralel yang mampu menggabungkan kecepatan dan kemanjuran.

Hibrida ini menggunakan multi-deme GAS di tingkat atas dan bawah. Di level bawah, tingkat migrasi lebih cepat dan topologi komunikasi jauh lebih padat daripada di level atas
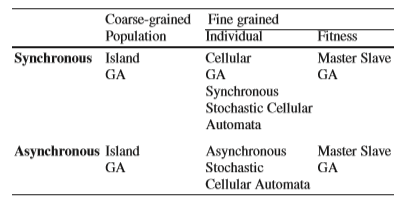
Kelas algoritma genetika paralel utama sesuai dengan ruang dan dimensi waktu mereka
C. Algoritma Genetika Hibrid (HGA)
Algoritma Genetika Hibrida dalam bagian ini dirancang untuk menggunakan heuristik untuk inisialisasi populasi dan peningkatan keturunan yang dihasilkan oleh crossover untuk Traveling Salesman Problem (TSP). Algoritma heuristik inisialisasi digunakan untuk menginisialisasi sebagian populasi; bagian yang tersisa dari populasi akan diinisialisasi secara acak. Keturunannya diperoleh dengan crossover antara dua orang tua yang dipilih secara acak. Heuristik peningkatan tur: RemoveSharp dan LocalOpt digunakan untuk membawa keturunan ke minimum lokal. Jika biaya tur musim semi maka yang diperoleh kurang dari biaya tur salah satu dari orang tua kemudian orang tua dengan yang lebih tinggi biaya dihilangkan dari populasi dan keturunannya ditambahkan ke populasi. Jika biaya tur anak lebih besar dari kedua induknya maka akan dibuang. Untuk shufing, nomor acak dihasilkan dalam satu dan jika kurang dari probabilitas yang ditentukan dari operator shufing, tur dipilih secara acak dan dihapus dari populasi. Urutannya secara acak dan kemudian ditambahkan ke populasi.
Algoritme berfungsi sebagai berikut:
• Inisialisasi sebagian populasi menggunakan Inisialisasi algoritma Historis • Inisialisasi sisa populasi secara acak
Langkah 2:
• Terapkan RemoveSharpalgorithm ke semua tur dalam populasi awal • Terapkan algoritma LocalOpt untuk semua tur dalam populasi awal
Langkah 3:
• Pilih dua orang tua secara acak
• Terapkan Crossover antara orang tua dan hasilkan anak
• Terapkan RemoveSharpalgorithm untuk anak
• Terapkan algoritma LocalOpt untuk anak
• Jika TourCost (anak) <TourCost (salah satu dari orang tua) kemudian ganti orang tua yang lebih lemah dengan anak
Langkah 4: Ganti satu tur yang dipilih secara acak dari populasi.
Langkah 5: Ulangi langkah 3 dan 4 sampai akhir dari jumlah iterasi yang ditentukan.
1. Crossover
Operator crossover yang digunakan di sini adalah sedikit varian dari operator crossover yang dirancang oleh DarrellWhitley. Operator makro menggunakan "peta tepi" untuk membuat keturunan yang mewarisi informasi sebanyak mungkin dari struktur induk. Peta tepi ini menyimpan informasi tentang semua koneksi yang mengarah masuk dan keluar kota. Karena jaraknya sama antara dua kota, setiap kota akan memiliki paling sedikit dua dan paling banyak empat sisi asosiasi (dua dari setiap induk). Algoritma crossover adalah sebagai berikut:
Langkah 1: Pilih kota awal dari salah satu dari dua-induk wisata. (Ini dapat dipilih secara acak atau sesuai dengan kriteria yang diuraikan dalam langkah 4). Ini adalah "kota saat ini".
Langkah 2: Hapus semua kemunculan "kota saat ini" dari sisi kiri peta tepi.
Langkah 3: Jika "kota saat ini" memiliki entri di daftar ujungnya, lanjutkan ke langkah4; jika tidak, lanjutkan ke langkah5.
Langkah 4: Tentukan kota mana di daftar tepi "kota saat ini", yang memiliki tepi terpendek dengan "kota saat ini". Kota dengan tepi terpendek termasuk dalam tur. Kota ini menjadi "kota sekarang". Ikatan rusak secara acak. Lanjutkan ke langkah 2.
Langkah 5: Jika tidak ada kota yang belum dikunjungi yang tersisa, maka BERHENTI. Jika tidak, pilih kota yang belum dikunjungi secara acak dan lanjutkan ke langkah 2.
2.Heuristik Inisialisasi
Algoritma Initialization Heuristics (IH) hanya dapat diterapkan ke TSP. Ini menginisialisasi populasi tergantung pada algoritma serakah. Algoritma serakah mengatur kota-kota tergantung pada koordinat xandy mereka. Tur-tur diwakili dalam daftar tertaut. Pertama daftar awal diperoleh dalam urutan input (InputList). Daftar tertaut yang diperoleh setelah menerapkan heuristik inisialisasi adalah "Daftar Keluaran". Selama proses penerapan heuristik inisialisasi semua kota di "Daftar Input" akan dipindahkan satu per satu ke "Daftar Output". Algoritma heuristik inisialisasi untuk TSP adalah sebagai berikut:
Langkah 1: Pilih empat kota, yang pertama dengan nilai koordinat x terbesar, yang kedua dengan nilai koordinat x paling sedikit, yang ketiga dengan koordinat y terbesar dan keempat dengan paling sedikit y- nilai koordinat. Pindahkan mereka dari "Daftar Input" ke "Daftar Keluaran".
Langkah 2: Dari antara urutan yang mungkin dari empat kota, temukan urutan biaya minimum dan ubah urutan empat kota di "Daftar Keluaran" menjadi urutan minimum.
Langkah 3: Acak elemen-elemen dalam "Daftar Input".
Langkah 4: Hapus elemen kepala dari "Daftar Input" dan masukkan ke dalam "Daftar Output" pada posisi di mana kenaikan biaya tur adalah minimum. Misalkan M adalah biaya tur sebelum penyisipan dan N menjadi biaya tur setelah penyisipan. Posisi penyisipan dipilih sedemikian rupa sehingga N-M minimum.
Langkah 5: Ulangi Langkah 4 sampai semua elemen dalam "Daftar Input" dipindahkan ke "Daftar Output".
Bergantung pada kriteria pengurutan pada Langkah 3 dari algoritma di atas berbagai hasil akan diperoleh. Hapus Sharp dan heuristik Local Opt diterapkan ke keturunan yang diperoleh dengan metode ini dan ditambahkan ke populasi awal.
3. Algoritma RemoveSharp
Algoritma RemoveSharp menghilangkan kenaikan tajam dalam biaya tur karena sebuah kota, yang diposisikan dengan buruk. Algoritme berfungsi sebagai berikut:
Langkah1: Daftar (TERDEKAT) yang berisi kota terdekat sebagai kota terpilih dibuat.
Langkah 2: Hapus Sharpremoves kota yang dipilih dari tur dan membentuk tur dengan N −1cities.
Langkah 3: Sekarang kota yang dipilih dimasukkan kembali dalam tur baik sebelum atau setelah salah satu kota di NEARLIST dan biaya panjang tur baru dihitung untuk setiap kasus.
Langkah 4: Urutan, yang menghasilkan paling sedikit biaya, dipilih.
Langkah 5: Langkah-langkah di atas diulang untuk setiap kota dalam tur.
4. Algoritma LocalOpt
Algoritma LocalOpt akan memilih kota q berturut-turut (Sp + 0, Sp + 1, ....., Sp + q-1) dari tur dan mengatur kota Sp + 1, Sp + 2, ...., Sp + q-2d sedemikian rupa sehingga jarak minimum antara kota Sp + 0 danSp + q-1dengan mencari semua pengaturan yang mungkin. Nilai p bervariasi dari 0 ton-q, di mana n adalah jumlah kota.
D. Adaptive Genetic Algorithm (AGA)
Algoritma genetika adaptif (AGA) adalah GAS yang parameternya, seperti ukuran populasi, probabilitas persimpangan, atau probabilitas mutasi bervariasi saat GA berjalan. Varian sederhana dapat menjadi sebagai berikut: Tingkat mutasi diubah sesuai dengan perubahan dalam populasi; semakin lama populasinya tidak membaik, semakin tinggi tingkat mutasi yang dipilih. Begitu juga sebaliknya, itu menurun lagi segera setelah peningkatan populasi terjadi. Prosedur Algoritma Genetika Adaptif keseluruhan adalah sebagai berikut:
Langkah 1: Populasi awal Kami menggunakan populasi yang diperoleh dengan pembangkitan angka acak.
Langkah 2: Operator genetik Seleksi: strategi elitis dalam ruang sampel yang diperbesar Crossover: operator crossover berbasis pesanan untuk prioritas kegiatan Mutasi: lokal operator mutasi berbasis pencarian untuk mode aktivitas
Langkah 3: Terapkan pencarian lokal menggunakan metode mendaki bukit iteratif di loop GA.
Langkah 4: Terapkan heuristik untuk mengatur parameter GA secara adaptif (mis., Tingkat persilangan dan operator mutasi).
Langkah 5: Kondisi berhenti Jika nomor pembangkitan maksimum yang ditentukan sebelumnya tercapai atau solusi optimal terletak pada proses pencarian duringgenetic, kemudian berhenti; jika tidak, lanjutkan ke Langkah 2.



Tidak ada komentar:
Posting Komentar